
Artificial Intelligence (AI) has become an integral part of various industries, revolutionizing the way we interact with technology. However, the effectiveness of AI systems relies heavily on the quality of the data used to train them.
Training your AI is as simple as adding your preferred training sources and you’d be ready to go in no time. But there are a couple of things you should consider doing to ensure better results from the AI responses. As the saying goes, "garbage in, garbage out."
In this article, we will explore the significance of training data and provide best practices and guidelines for using good sources to achieve accurate and valuable AI outcomes. These tips can be used to optimize your existing content as well as when creating new content.
Training source best practices
- The AI is only as good as the training sources you add.
- Review your content before adding it as a source.
- Is it correct, clear, up-to-date, and comprehensive? Is it relevant?
- This review can help identify gaps in your content as well as updates that might be needed.
- Have a scannable structure.
- Use rich formatting. Make sure your content has headers, sections, numbered lists, bullet points, etc.
- Have concise paragraphs. Break large chunks of text into smaller sections.
- This is good practice in general. It makes your content more readable not just for the AI but for your customers as well.
- Explain key terminology and acronyms.
- Make sure you explain any key terminology and acronyms whether they be common in your industry or specific to your company or product. Once again, this is good for the AI just as it is good for your users.
- Add written descriptions to accompany visual content.
- While visual content can be helpful, especially in the case of walkthroughs and explainers, the AI cannot read screenshots, photos, or videos.
- Include a breakdown of the content using rich formatting and a clear structure with step-by-step instructions.
- Adding descriptions to visuals and transcripts to videos is also great for accessibility so it's a win-win!
- Do not use user-generated content (eg. community forums or old customer support tickets).
- We elaborate on this down below.
- Avoid duplicate content.
- Have a single source of information as much as possible. This will ensure consistency in the answers and linked sources provided by the AI.
- Think twice before doing any bulk uploads.
- As the saying goes, quality over quantity. Consider the quality of the content and its use case.
- Ps. There might be a better approach (ie. integrations) so don’t hesitate to contact our support team.
- Always check that the source is indexed correctly.
- For each source listed under your global training sources or within your topics, you can select Show indexed items from the Actions menu. You can then click View content for each indexed item to review the exact content that has been ingested by the AI. This is great for troubleshooting.
- Continuous improvement
- Add your sources and test your AI. As you keep asking questions to test and improve the AI, you can identify any gaps.
- Which questions is the AI not able to answer because there is no information about it? Which answers are outdated and need an update? What are the most frequently asked questions?
- It is strongly advised to have your knowledge base in a single language.
- The language itself doesn’t matter. This is because there is something called “Language bias” in AI which means if you ask a question in Dutch, it will strongly prefer an article written in Dutch as opposed to English, even though it doesn’t contain the correct answer. So mixing languages within one knowledge base can lead to a worse performance of the AI.
Types of training data
To guarantee that AI systems receive the most effective and comprehensive training possible, we provide support for a variety of source types such as website content, Q&As, and files.
Website content
Website content is an ideal resource for training AI since it tends to be clear and concise. The well-written and thought-out nature of website content makes it perfect for this task. The detailed analysis and descriptions present on websites provide valuable information that can be used to feed machine learning models.
Knowledge bases that contain help articles can be a valuable resource for training purposes. Like website content, they are also well-written and thought-out. Furthermore, they can be updated regularly with new information, ensuring that the AI always has access to the latest and most accurate training material.
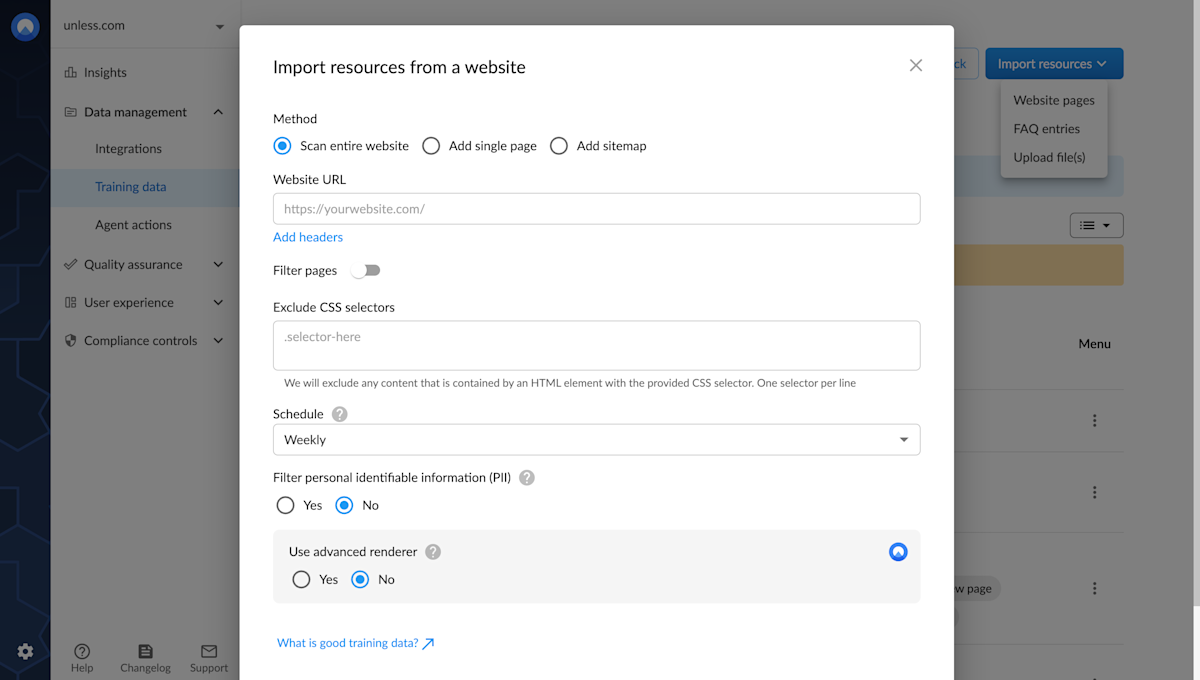
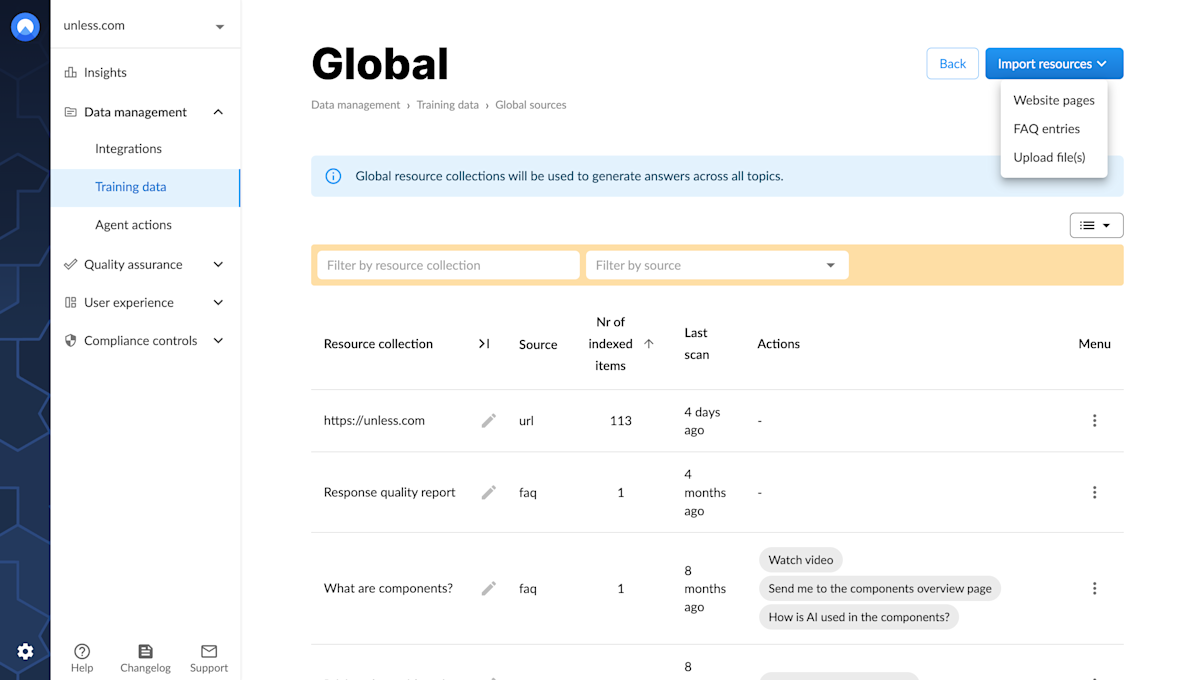
When using our AI, you have the option to expand your training set by manually adding individual pages or by allowing the AI to crawl your entire website through the sitemap.xml file. Our include/exclude feature gives you more control over which pages should be included or excluded during the crawling process, enabling you to tailor the training data according to your specific needs and preferences. By making these decisions, you can ensure that the AI is trained on the most relevant and accurate data, which can improve its overall performance and accuracy in the long run.
Properly using headings, also known as H-tags in HTML, is crucial for creating structured and organized content. By using headings, you can segment your content into logical and easy-to-follow sections. This not only enhances the readability of your content but also improves the AI's ability to identify and extract the most relevant information. In other words, headings are an essential tool for optimizing your content for both human readers and search engines. So, it is important to understand the different types of headings and when to use them, to ensure that your content is well-structured and easy to navigate.
Q&A entries
Our system offers the option to manually add Q&A entries directly into the training set. You can add, update, and delete these entries in real-time. Adding a list of your frequently asked questions is an excellent way to instruct the AI into offering specific answers to common queries.
The exact phrasing of the questions in the training data is not crucial, as the AI seeks to understand the context and meaning of the question rather than the specific words used.
Q&As can also be utilized to provide additional information or instructions, enhancing the accuracy and relevance of AI-generated responses.
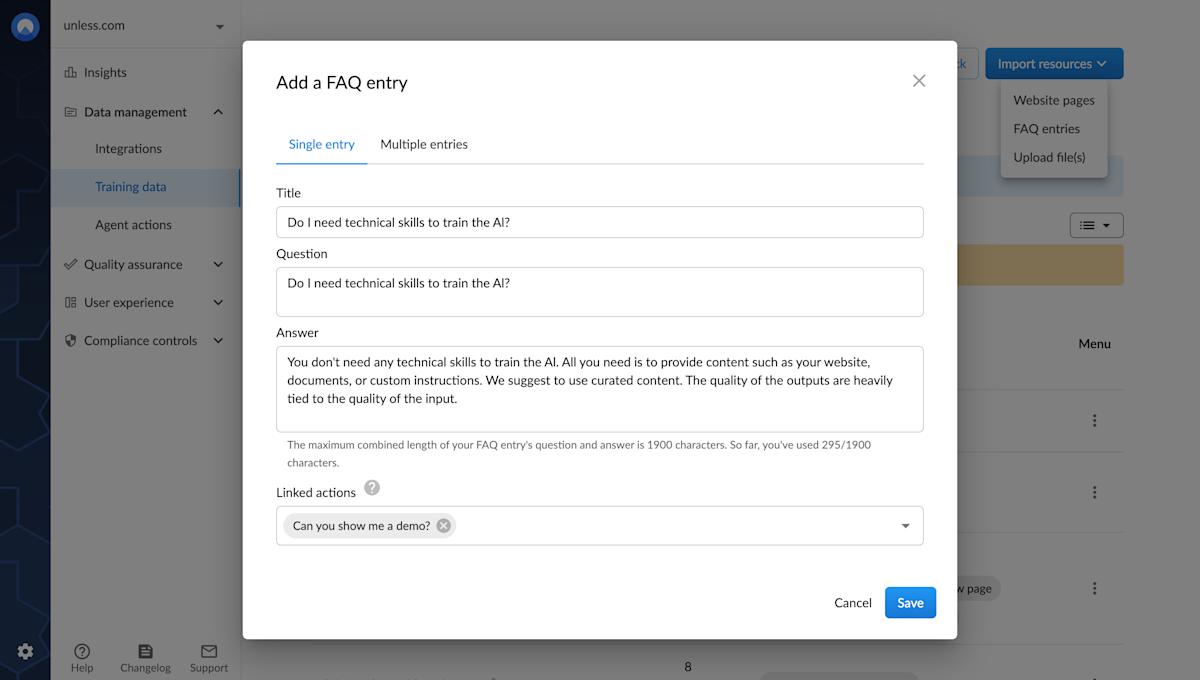
In addition to the benefits of using Q&As for training AI, there is another valuable aspect worth mentioning. You have the flexibility to include temporary Q&As in the training set, providing a way to override specific responses temporarily under certain circumstances.
By adding temporary Q&As, you gain the ability to address transient situations effectively. And you can simply remove them, once they are no longer needed. For example, if a particular feature is currently experiencing issues and users are frequently asking about it, you can create a temporary Q&A entry explaining the situation. The AI will then take this information into account and provide appropriate responses until the issue is resolved.
Files
Files can be a valuable source of knowledge, similar to website content. The supported file types are: PDF, Docx, CSV, and markdown, as well as Google Drive files.
Like web pages, files should have appropriate headings and well-structured content for effective AI training. This means that the headings should be descriptive and accurately reflect the content that follows. CSVs in particular must contain a column named "title" and a column named "description" in the first row.
Moreover, it is important to ensure that the content is organized in a logical and coherent manner. This can be achieved through the use of subheadings, bullet points, and other formatting techniques to break up large chunks of text into more digestible pieces.
Keep in mind that while images can be indexed, the AI can't "read" them so contextual text is important. Additionally, tables with extensive data might not yield optimal results, as the AI thrives on written content with contextual meaning.
Avoid user-generated content
While user-generated content, such as questions and answers from help desks, community forums, or old customer support tickets may seem like valuable information to train the AI, it comes with some significant drawbacks.
- Customer support tickets may contain irrelevant context, leading to inaccurate AI responses. For example, if a user asks about using his own Mastercard for credit card payments and the AI is trained on this data, it might incorrectly assume that Mastercard is the preferred credit card used by the company.
- User-generated questions may remain online for extended periods, leading to outdated information.
- Bug reports might not accurately represent the actual behavior of the system, potentially resulting in misleading AI responses.
Improve your sources
It's usually easy to tell if your sources need improvement. However, it is harder to know where to begin and with which sources. This is where the Quality score comes into play.
Resource quality score
When you're looking at a list of your resources, there will be a column on the right-side, titled Quality. This is an indication of the quality of your content in regards to AI friendliness, aka AI readability.
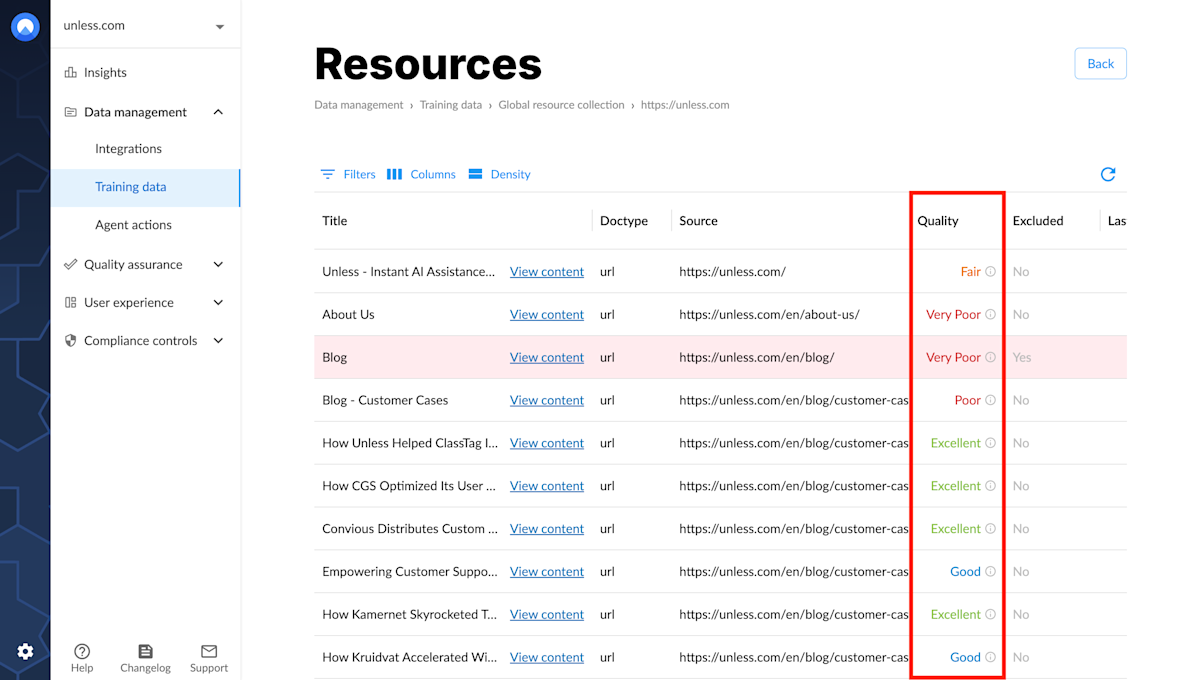
Once you're on this page, we suggest sorting the list by quality (from Very poor to Excellent) which should give you an idea of where to start, at a quick glance.
This view might also help identify patterns in your resources. For example if a certain type of content or section of your website isn't performing well, the issue might have to do with the formatting rather than the content.
Document metrics
The next step is to click View content to see more information. This view gives you an idea of how the AI "sees" your content. For example, you might notice that the content is broken into sections (or maybe it is one big chunk). This is why it's important to use headers to break your text into sections as it improves readability, not just for the AI but for people as well.
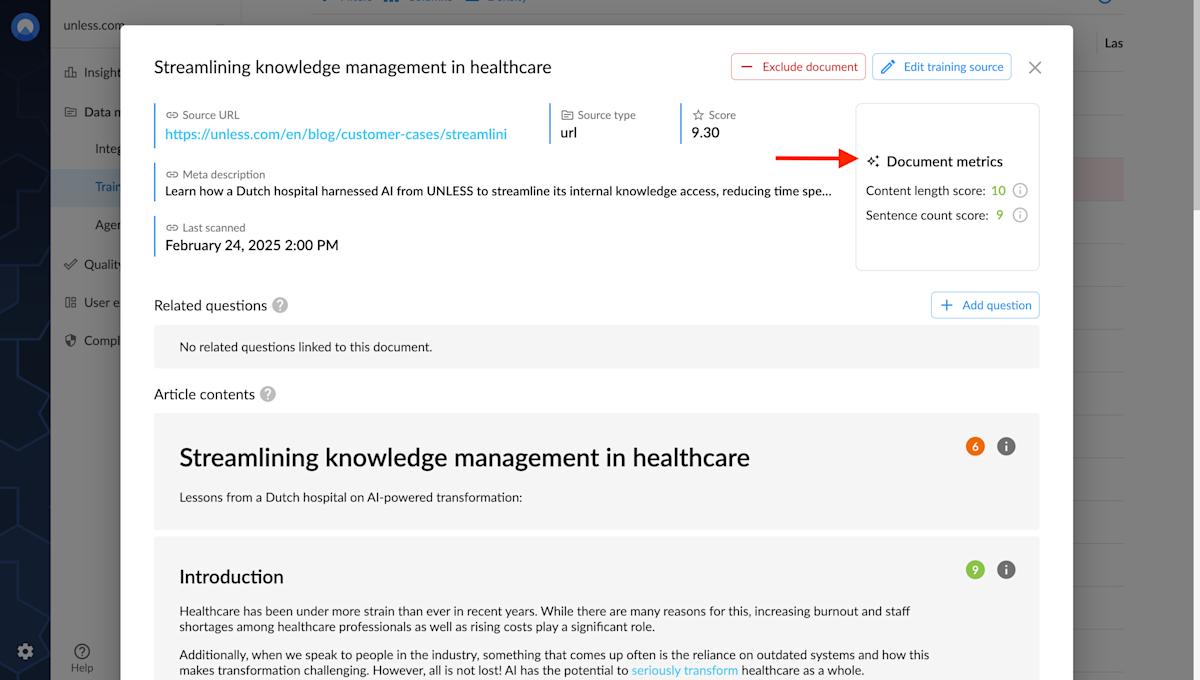
On the top right corner, you will see the metrics that factor into the quality score for this document: content length and sentence count (%). More metrics and suggestions for improvement are in the works.
When viewing content, you can also choose to Exclude a document. And if you change your mind, you can simply click Add document. For example, in the case of the Unless website, we chose to include blog articles in the training data but excluded the main blog page which didn't have any content of its own.
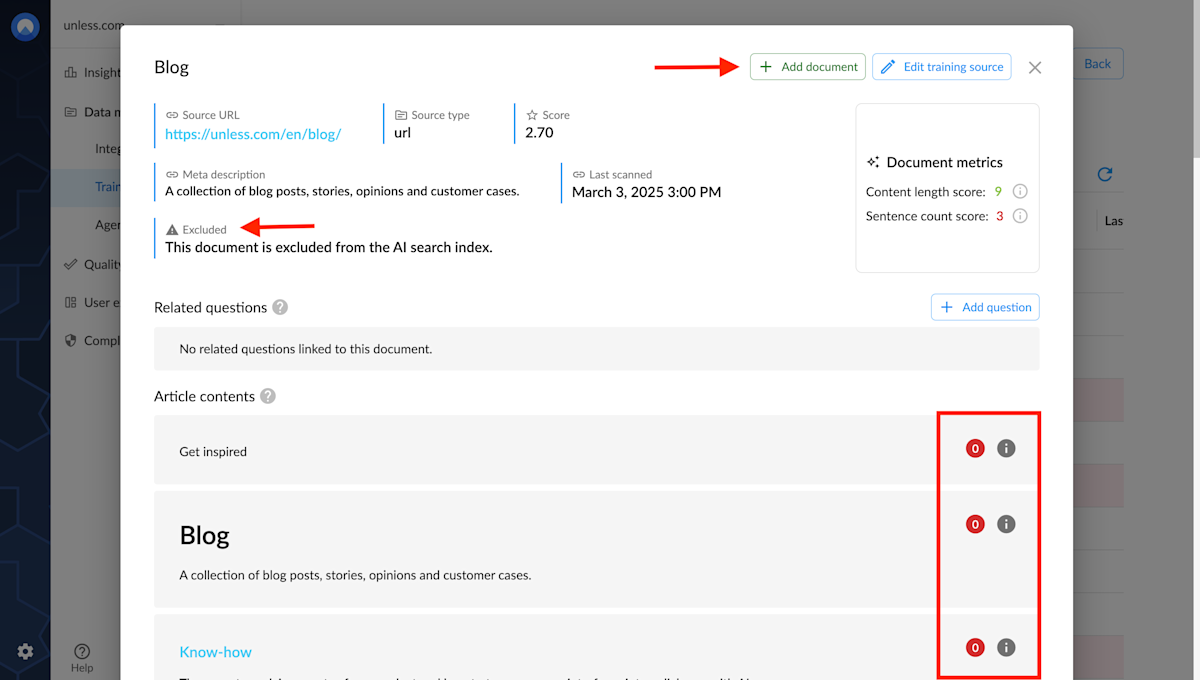
Section metrics
In addition to the overall document metrics, each section has its own score as well. This is important since (just like in the screenshot below) a document can have a mix of good and poor sections. This way when you are adjusting your content, you know exactly where to direct your attention.
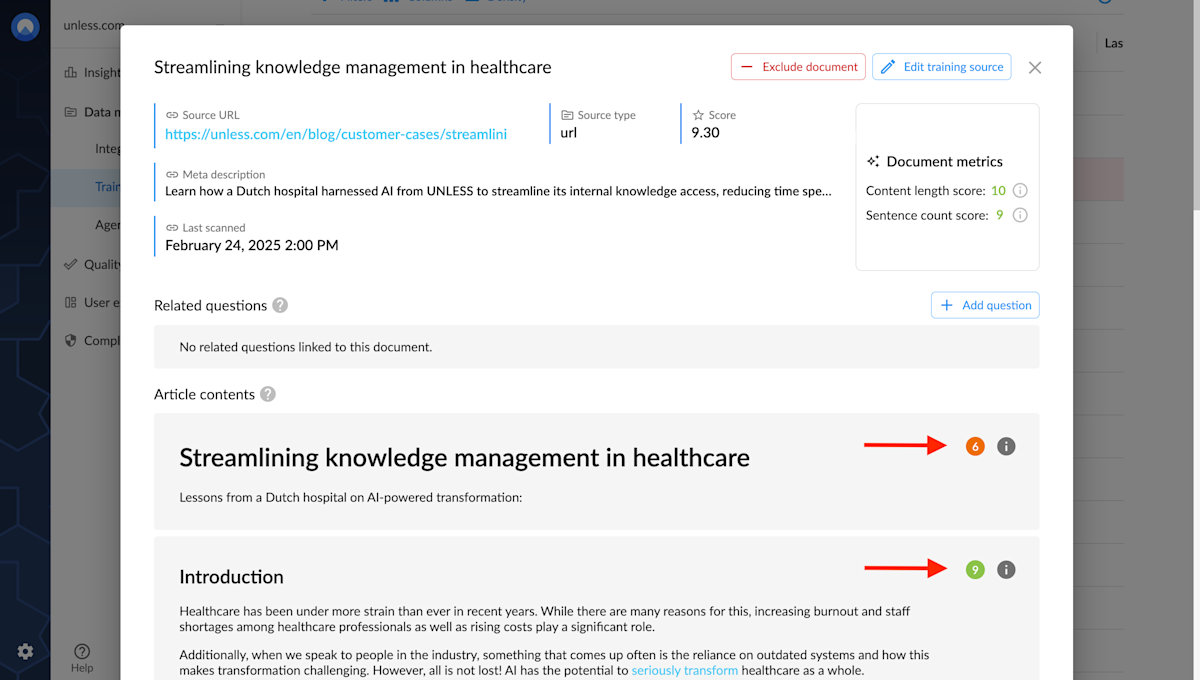
If you notice some clutter on a page (ie. header, footer, table of contents, etc.) that gets ingested with every page, you can click the Edit training source button and add a list of CSS selectors to be excluded.
Content optimizer
We also have a content optimizer that your account manager can turn on for your resource collections when needed upon request. The optimizer is meant to improve the formatting of your sources (break large text into chunks, maybe add headers, etc.) so they are more readable by the AI, resulting in a better quality score. It doesn’t affect the original sources, but you can see the original vs. optimized versions in Unless when previewing a source.
Conclusion
The quality of training data significantly impacts the performance of AI systems. By carefully selecting and curating sources such as website content, PDFs, and well-structured Q&As, you can ensure that your AI is trained with accurate and relevant information.
Avoiding user-generated content helps prevent misinformation and outdated data from influencing AI responses. Plus, you can always improve your existing resources with the help of the quality score and the content optimizer.
By following these guidelines, you can unleash the true potential of AI and enhance the user experience for your customers. Additionally, as mentioned earlier, a lot of these recommendations are also just good practice in general, not just for the AI but also for your users.


